How to deal with the PII data within the application
Introduction
In the world of the GDPR, data privacy is one of the highest priorities nowadays. From time to time we see, that an enormous amount of sensitive data are leaked, which caused big damage to companies, as well to each and every people which data was leaked.
Sometimes, it's due to poor security, but mostly it's due to laziness, and lack of care in handling data. Common cases of data leakage in real life, e.g. in an office, were caused by keeping sensitive customer data accessible by writing it on sticky-notes and attached them to a computer monitor. This made it possible for anyone nearby to potentially "steal" the data. This includes customer data, login data for internal systems, as well as important information regarding company-related aspects.
Often the reason for this type of behavior is that employees do not always have the right place to keep this type of data. Of course, developers can create notes functionality in their systems, but further data may be leaked either by employees or by inappropriate transfer of notes to unauthorized people.
General content
The PII abbreviation stands for personally identifiable information. It is any data that can be used to identify a specific individual. There are different types of PII, we can break them down into several main categories:
- Personal: It contains data such as name, addresses, mobile phone, e-mail as well as data related to the age of a given person.
- National: It contains data such as Social Security Number (SSN), passport data and data related to the driving license number.
- Financial: It contains data such as banking information and credit card information.
- Technical: It contains data such as IP addresses, usernames, passwords, urls and etc.
- Others: Moreover, we have more other categories as well.
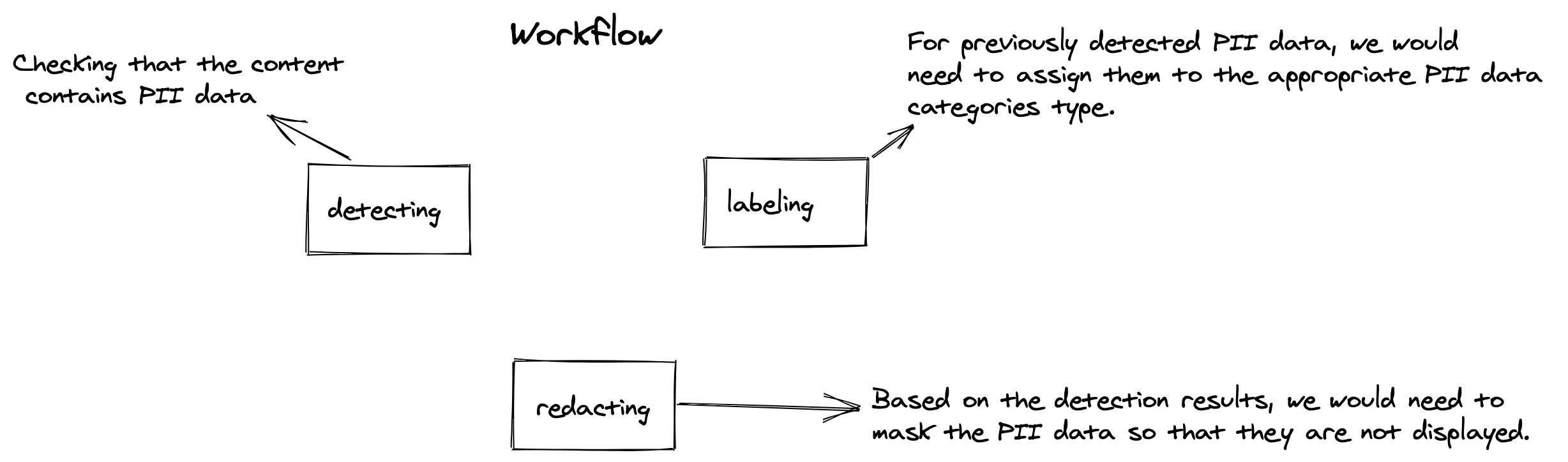
Fortunately for our developers, we have several existing tools/approaches/techniques to allow:
- detecting: to check if the data consists of the PII data.
- labeling: to assign detected data to one of the many existing PII data category type
- redacting: to mask/redact the data which was detected as PII data.
Scenario
Let's assume the following scenario, that we have an application for a medical facility. Pretty standard stack with Ruby on Rails, hosted on the Amazon Web Services(AWS).
- The facility has both accounts for medical staff, vendors who sell medical packages, and patients.
- Salespeople can create notes about potential customers to improve their work by recording relevant information to help sell a particular medical package.
- The question is how to secure the application from entering sensitive customer/patient data so that it is not in publicly available notes between vendors.
- We would not like, for example, agent Y to see that agent X has entered the customer's credit card number that should be charged for buying the package, or the customer's personal information. Public notes are not the place for this kind of thing.
My main programming language is Ruby, so let's check out what options do we have.
Research on existing tools for Ruby
Ruby is a mature language. It has a large and active community, and many libraries (called gems) that streamline and speed up the development process.
Gems
Searching on Google for gems that deal with PII data, we don't get many results. The library that seems most promising pii-detector, created by Shopify, appears to be abandoned (i.e. the gem is not maintained, not even a functioning page on the Github).
Beside it, we can find Logstop, which supposed to keep the PII data out of your logs. Looks promising, however, it does not handle most of the PII data category types. And we would like to detect and redact data before it will be saved to the database, on the logs layer.
Regex
It is fairly easy to write a regex to detect numbers, or a specific number of numbers, so credit card detection using a regex, would be fairly simple, same for a URL, however it is possible to write a valid regex for residential address detection? No each and every kind of PII data, has easy pattern to be matched via regex. Sometimes to detect PII data we need to know some context, not only possible pattern matched wording structure.
Separate products
There are some SaaS products for detecting PII data, which will help to detect PII data by analyzing our data. However, pricing for such tooling is pretty expensive. Sometimes it will take more, than your yearly bill to host your application.
Cloud based solution with ML
In order to be able to analyze our notes, also based on the context, to catch individual phrases with greater accuracy, it would be worth using ready-made ML models to identify PII data. As we are already using AWS in our scenario, it would be worth looking around for some service from their services range (over 200 services).
My attention was drawn to the Amazon Comprehend service which enables sensitive data detection based on ML. It's a pay-per-use solution, so you don't need to pay a monthly fee to access the tool. With this approach, we could build a custom validator that would analyze a note before creating it, assign it to the appropriate PII type category, and then redact that note and save it to the database with both redacted and unredacted content. Fortunately, there is an SDK for Ruby from AWS, so we can use it in our project.
Next steps
For next steps, will be getting familiar with Amazon Comprehend, and simply makes our hand dirty with this AWS service. For the next couple of blog posts I will focus on:
- showing the possibilities of Amazon Comprehend in the case of PII data.
- showing ruby/rails implementation of analyzing content to detect PII data.
- labeling detected data to the proper PII data type.
- redacting detected PII data (both with Ruby, and AWS approaches).
- Train our custom ML models to detect custom PII data, which will are not supported by the Amazon Comprehend.
Summary
- We learned what a PII data is, how and what types of PII there are.
- There are no out-of-the-box libraries that will allow us to perform a task immediately.
- The regex approach will not necessarily work on data that is based on context, or more advanced patterns.
- We've found a potential tool which ensures a robust and long-lasting quality solution for our needs, which is very cost-effective.